Last time we did make a server and connected using Telnet client. This time we are going to create a client using Java and try to connect to our earlier made simple server

To get the output you have to first run the Server Program. Then while its running run this program as well. Then it will connected to the server and display the following.

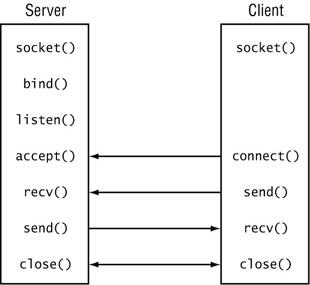
O key, Lets go straight to the coding part since there is no much to discuss.
As creating the simple server this too has 3 steps.
- Opening the client socket
- Create I/O stream (Read and write).
- Perform Communication and finally Close Socket
So few things to remember from the earlier post. The server was created in the localhost and the port was 9000. Here is the code for Simple Client program.
import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; import java.net.Socket; public class MySimpleClient { public static void main(String[] args) { try { Socket ClientSoc = new Socket("localhost",9000); //Step1: Opening Client Socket InputStream is = ClientSoc.getInputStream(); //Step 02: Createing I/O stream BufferedReader br = new BufferedReader(new InputStreamReader(is)); String data = br.readLine(); //Step 03: Performm communication System.out.println("Date time recived :" + data); ClientSoc.close(); //close client socket } catch (Exception e) { e.printStackTrace();; } } }
